Skydive!
November 20, 2004 - Reading time: 2 minutes
Well, I went skydiving today with two co-workers. Skydiving is one of those things that I always sort of assumed I would never do (I mean why would somebody jump out of a perfectly good airplane?).
It was actually pretty fun. There's a lot of waiting involved, and you have to sign several pages of "if you fall and break your leg, don't come running to us with legal documents." After that, you wait around a while. There was a short instructional video, narrated by some guy with a comically long beard, that was about 50% "why you shouldn't sue us" and about 50% "hey, come jump out of this airplane using our patented and totally safe harness; don't worry about any of that other stuff I just said."
We did tandem jumps, which was nice for the first time because instead of having parachutes strapped to our backs, we had trained professionals strapped to our backs (the trained professionals had parachutes on their backs). It was really fun; everyone there was very laid back and seemed to enjoy what they were doing. The worst part was the plane ride up, which was very uncomfortable. The freefall portion was really cool; it was very scary at first, because my brain kept telling telling me "you were just kicked off an airplane 15,300 feet off the ground, and now you're falling toward it at 120mph." Once you remind your brain about the trained professional and the parachute, it's an extremely cool feeling. The harness assembly was bulky, awkward, and uncomfortable, but it did its job quite well and meant that we didn't have to take any sort of classes beforehand. Landing was also relatively easy, though presumably that's a dangerous part. The people not doing tandem jumps were doing some scary looking acrobatics and coming in for pretty hard landings, but they were nice to us first-timers (thanks!).
Overall, it was totally worth doing, and I would do it again any day. In fact, I might do it again at some point.
How to do space right
November 6, 2004 - Reading time: 14 minutes
Note, 30 May 2020: As with other space-related posts from this era, 2020 me doesn't totally agree with 2004 me, and there are some very confident statements that seem a bit questionable, but overall the post isn't bad so I'm posting it anyway.
I visited the Kennedy Space Center tourist attraction last week, which was pretty fun. It's an interesting place to go and look at authentic-looking replicas of cool space technology, and they have a big gift shop.
On the way back, David and I were talking a bit about the space program in general, and it got me thinking about current events in the space program.
In a time when NASA is thinking about retiring the Space Shuttle early, the 35th anniversary of man's first steps on the moon pass by with barely a mention, and Russian Space Shuttles are turning up abandoned in the desert, I think it's important to ask: what's the deal with the space program? Why do we have it? What's the goal? And what do we do
the Space Shuttles?
As I've said before, the Shuttle was a great first step, but it's time to move on.
But to where? Over the last couple of decades, when we should have been looking forward, we've been focused intently on low Earth orbit. Without clear goals for the future, we experimented with a few neat ideas, but nothing really took off (so to speak) because they weren't any better than the Shuttle at performing the same tasks, and they didn't really take us any farther than the Shuttle could. So NASA dumped some money at them, learned a few neat things, came up with some nifty ideas, and then pitched them all in the trash. (In theory, all of those ideas are recorded somewhere, but for practical purposes, my guess is that most of them are permanently lost).
So now we're left with aging (and ailing) Shuttles, but nothing to replace them. Our esteemed president has suggested a new mission (first the moon, then Mars), but we don't have the slightest idea how to do it.
How is that possible? I mean we've already been to the moon, right? So we know how to do that, right? Wrong. We've forgotten how, because we've totally ignored it for 20 years. One would assume that all of the data still exists somewhere, but it's more likely that the data has been lost, or destroyed, or purged. And the people who worked on the Apollo project have long since retired or died, and since there was no continuing work done, none of that information was passed on to the next generation. So we have to learn it all over again.
In the last twenty years, we could have been learning how to keep astronauts in space for months on end without any intervention from Earth-based assistance. We haven't figured that out yet - the small crew of the ISS spends all of their time desperately trying to keep the thing working; without frequent supply missions with food, water, and spare parts, the ISS would kill its occupants and come tumbling to Earth. And it's not even technically in space - it sits in the layer of plasma that surrounds the planet. (If this doesn't seem like an important distinction, ask the crew that decided to run the US-built solar panels at 130-180V why plasma is different than space).
There are many reasons for our lack of progress, but I think that it comes down to two main reasons: lack of defined goals and a subcontracting fetish. I'll address the two separately.
All dressed up and nowhere to go
The prime of NASA's existence was when the US was focused on getting to the moon. At that time, the agency had a concrete goal and the means to get there. The best science and engineering in the world was happening at NASA, and because of that they attracted the finest minds in the world. As we made our first stabs at the moon, we inspired a generation of students to become scientists and engineers - through the 80s and 90s we reaped the benefits with amazing scientific discoveries and engineering feats. This is starting to taper off; our generation's inspiration comes from people who dropped out of college and became millionaires in the personal computer industry: hardly positive role models.
Though getting to the moon was an excellent goal and worthy of doing, we went about it for the wrong reasons: once we got to the moon, Americans immediately lost interest and wondered why we needed to be spending all of that money playing low-gravity golf and lugging rocks around space. Indeed, even NASA seemed to have a hard time justifying itself once we had been there a few times, and we cut the number of moon missions short. Thankfully, there were still communists to compete with, so somebody got the great idea of making a reusable launch vehicle (also an excellent goal worth pursuing), and NASA jumped on the task.
The only problem was that while a reusable launch vehicle might be practical, it wasn't all that exciting. Indeed; it was named the "Space Shuttle" precisely to conjure up images of routine, uninteresting voyages in to space: the Shuttle was to be means to an end, a way to haul the interesting stuff in to space. So we came up with the Shuttle, and everybody looked around again for something to do, but couldn't find anything: NASA had already expended all of its political capital justifying the horrendous budget overruns the Shuttle had produced, and explaining why it was so expensive and non-routine to launch, and couldn't get congress to give them any more money until they made it cheaper.
Fast forward twenty years, and here we are still trying to do that: the interesting work has all been done, and all of the great minds that NASA attracted in the 1970s and 1980s have all left to better paying, more secure jobs in the private sector. The underpaid, overworked subcontractors remaining do a great job under the circumstances, but they're doing exceptionally non-glamorous (and mostly thankless) work, with low-level (at best) scientific gain. NASA, once a powerhouse, lies slowly decomposing in the wide-open spaces it once filled.
Government == Bad?
People seem to have an aversion to government employees. I've never understood it, but it's there, and it's hit NASA hard. The end result of this feeling, of course, isn't to reduce the size of government per se; rather the standard reaction is to subcontract out government jobs. This way the size of government is technically smaller, though as a general rule the number of employees doesn't really drop, and the cost generally goes up.
NASA's prime contractor for Space Shuttle operations, the United Space Alliance, sports the following scope of work:
At the Johnson Space Center in Texas:
- Flight Operations
- Astronaut & Flight Controller Training
- Space Shuttle Flight Simulator Operations
- Mission Control Center Management and Operations
- Mission Planning, Flight Design and Analysis
- Space Station Operations and Utilization
- Flight Software Development
- Flight Crew Equipment
At the Kennedy Space Center in Florida:
- Vehicle Modification, Testing, Checkout and Launch Operations
- Support U.S. and Trans-Atlantic Emergency Landing Sites
- Ocean Retrieval of Solid Rocket Boosters
- Space Shuttle Logistics Depot - manufacture, repair, and procurement of Shuttle hardware and ground support equipment
... so basically, they do everything. Why do we need NASA again? All they seem to do is manage subcontractors and hand out money.
The fact is, subcontracting isn't the way to do science. Subcontractors spend half of their time justifying their existence, and the other half falsifying timesheets to maximize their paychecks. Despite any claims otherwise, much of the United Space Alliance's often mentioned $400 million per launch savings comes from cutting corners on safety and reducing staff levels in important areas such as pre-launch checking.
Non-governmental organizations, either privately held or publicly traded, are in business first to make money. That's what business is about: profit. At first glance, it seems like an excellent way to save money; if the corporation sees a way to operate more efficiently to save money, it will. Right? Of course: but remember that priority one is making money; safety, quality, and reliability straggle in at distant second, third, and fourth. United Space Alliance (hereafter USA) is not interested in the science. They aren't interested in discovery. They aren't interested in redesigning the Shuttle to be lighter, safer, or stronger. They're interested in removing pre-launch checks to save $20 per launch. They're interested in their award fee. And most importantly, they're interested in keeping their contract when it comes up for review: $12 billion over ten years is what they want.
Steps for success
This is getting long, but I feel very strongly about it. I feel that NASA shouldn't be doomed to irrelevance; there's so much we can learn from space that we shouldn't just abandon it. So how should we proceed? I'm glad you asked:
- Start with a clear objective. The moon to Mars thing is good: establishing a permanent base on the moon and then proceeding to Mars is really three parts, all important. Since the moon is several days away, it forces us to actually do it right: stuff has to work, and the base has to be self sustaining, because the residents can't just jump in the Soyuz and head back home if there's a problem. The issue, of course, is that we don't really know how to create a self sustaining environment yet. Remember Biosphere 2? Didn't go over so well. So first we have an opportunity for NASA to do some good science and long-term testing here on Earth. While we're doing that, the rocket scientists can get together and figure out how to carry whatever the biosphere 3 people come up with to the moon, and put it together. That's launch vehicles, orbiters, a few unmanned orbital missions to the moon to select a site, and so on. Once all of that is running, the third mission is to take everything we've learned and use it on Mars. That isn't the simple matter of duplication, since Mars is much farther away, and has very different conditions. All of this is great science waiting to happen, and we'll learn a lot about our planet while we're at it.
- Be honest when asking for money. Part of the problem with the Shuttle and (to a lesser extent) the Apollo missions was their huge costs. There's some speculation that these costs were known from the beginning, but nobody told Congress because they knew that Congress wouldn't fund the programs if they knew how much the programs would cost. That tactic worked at the beginning, but it crippled the programs in the end as Congress insisted on massive cost cuts. Start out with realistic numbers, and stick to them as much as possible. Don't make promises you can't keep.
- Sell the programs to the public. This is the most important part. A space race with the Chinese would not be productive. Saying "Why? Because it's there" won't work either. And the current president is not the kind of person that can say "we choose to go to the moon." How do you sell it? That's a good question. Let me know if you figure it out. Maybe if we tell everybody that gay Martians are performing abortions, we can talk the American public in to the whole thing.
- Let NASA do the work. We've seen what subcontractors can do. The organization will be better, faster, and cheaper if it's a single organization, not a kludge of competing subcontractors.
- Don't require outside assistance. The International Space Station is a noble effort, but depending on others is a recipe for disaster (as we've seen with the ISS). That's not to say that we should exclude others; we'll be better off if we can attract the best minds from around the world. However things will go much more smoothly if the entire project is the work of a single agency.
We shouldn't stay on our planet forever. It's human nature to explore, discover, and expand. There's still plenty to do on Earth, but we also need to start making tentative steps off the rock. It won't be cheap, it won't be easy, and it might be a little dangerous: but the payoff will be profound. We can make it happen, but only if we try. Let's get started.
WHAP! GAAAG!
August 5, 2004 - Reading time: 7 minutes
Note: This is copied from somewhere, and I can no longer find the reference. If someone has the original article I'd love to properly cite it. It's funny anyway, just be sure that I'm not this funny.
That's acronym-ese for "We Have A Problem! Good Acronyms Are All Gone!" Acronyms are easy for any kid who knows his ABCs. But which ABCs? Atanasoff-Berry Computer? Automatic Bill Calling? Airborne Battlefield Computer? Activity Based Costing? Agent-Based Computing? Aerospace Basic Course? Approval By Correspondence? Automatic Bar Code? Airborne Communications? Army Battle Command?
This is just the sort of thing I deal with all day at work. In government, everything is an acronym. Add to that the fact that I am an electrical engineer, and electrical engineers are lazy by nature and abbreviate everything, and you have a Real Problem - RP - but not a Rapid Prototype, Recommended Practice, Reuse Project, or Remote Pilot.)
It's a real alphabet SEWP (Scientific Workstation Procedurement, not to be confused with SEWC - the Space and Electronic Warfare Commander, or SEMP - the Systems Engineering Management Plan) out there.
A quick example: Asynchronous Transfer Mode is a high speed voice and data network - people who use it call it ATM, but Doing So (DS is a Digital System, Development System, Distributed System, Design System, Data System, Directory System, Dictionary System, Distribution System, Detection System, Defense System, Deposit System, Dynamic System, Dynamic Simulation, Dynamic Skeleton, Dynamic Situation, Digital Service, Digital Synthesizer, Digital Signature, Digital Speech, Digital Sense, Digital Scene, Data Service, Data Storage, Data Simulation, Data Segment, Database Specification, Design Stability, Destination Service, Double Sided, Defense Software, Digital Scan, Display Station, Delivered Source, Dedicated Security, Distributed Storage, Deep Space, Deployment Schedule, and more) might Inadvertantly DIsappOinT (IDIOT) those who hope that it will dispense cash from your CD-ROM drive. Not Yet, Anyway (NYA). Thank Heavens (TH) ATM won out over the Canadian ISDN standard, Basic Rate Access (BRA).
"MS" means Microsoft. Or Millisecond. Marine Systems. Marine Safety. Material Safety. Material Support. Mission Support. Mission Specific. Management of Software. Major Subordinate. Message Store. Milestone. Most
Significant. Modem Sharing. Mobile Subscriber. Modeling and Simulation. Multisensor. Multispectrum. Metered Services. Message Security. Minimum Security. Maximum Security. Miniature Satellite.
But the Absolute Worst For Used-up Lingo (AWFUL): "PC;" there are more than listed here, but I got sick of tracking them down: Procurement Center, Procurement Contract, Principal Contract, Prime Contractor, Primary Cause, Physical Configuration, Physical Connect, Politically Correct, Posturally Correct, Permit Compliance, Personal Conferencing, Program Coordinator, Program Change, Program Compliance, Program Cost, Program Control, Production Control,
Parts Control, Private Control, Process Control, Process Controller, Process Change, Program Counter, Pulse Code, Posix Conformance, Photochemical, Photoconductive, Pocket Calculator, Principal Consultant, Printed Circuit, Project Coordinator, Password Call, Policy Creation, Policy Certification, Portable Command, Paging Channel, Peripheral Component, Protocol Council, Protocol Capability, Printer Command, Plug Compatible, President's Council, Packet Circuit, Personal Capability, Probability of Correct, Production Change, and Protected Communication.
Oh -- I almost forgot -- Personal Computer.
Careful Problem Analysis (PA ... or is that Price and Availability? Programmer/Analyst? Program Authorization? Privacy and Authentication? Partial Agreement? Preparing Activity? Pass Along? Product Assurance? Public Address?) ... wait, I got sidetracked. Let's Try Again (TA ... Technical Architecture? Transfer Agent? Traffic Analysis? Target Acquisition? Travel Authorization?):
Careful And Constructive Analysis (CACA) leads me to conclude that the fault, Dear Readers (DR; not Data Requirement, Decision Review, Deficiency Report, or Disaster Recovery), lies not in our acronyms but our alphabet. It's just Too Darn Short (TDS ... Technical Data Storage? Time and Date Stamp?). Only
23,700,000,000,000,000,000,000,000,000,000,000,000,000 acronym possibilities; the Department Of Defense (DOD, but not Direct Outward Dialing) probably invented that many Last Week (LW).
If Over Acronymization (OA ... not Obligation Authority, Office Automation, Operational Assessment, Office of the Administrator, ...) is a Problem for Overworked Computer Operators (POCO; Proof of Concept; Point of Contact; Public Operator's Code...), it's worse when you network. Computer Programmers (CP ... or Ceiling Protocol, Certificate Policy, Change Proposal, Command Post, Conditional Priority, Crypto Peripheral) don't speak in English; they do it in MIME (Multipurpose Internet Mail Extensions). And Speaking of Protocols (SP is a Security Plan? Security Protocol? Software Product?), X (as in X.25, X.400, X.500) should only be used to mark the spot, or videos you can't show your children.
If you're a FED Using Personal computers in a network (FEDUP ... not to be confused with FEDEP, the Federal Execution and Development Process), forget it. If you're asked for "NT," do you install MS' New Technology (or N-Ten) operating system, Network Termination, or Naval Telecommunications?
Working at the FAA (Federal Aviation Administration? Fund Administering Activity? Functional Analysis/Allocation?) is the lazy EE's (Electrical Engineer's) dream ... or nightmare. After all, why Say Something (SS ... not Signaling System, System Specification, Subsystem Specification, Segment Specification, Selective Service ...) when you can Abbreviate It (AI ... Action Item? Inherent Availability? Adapter Interface? Air Interface? Application Interface? Automatic Indexing? Analog Input? Um ... Artificial Intelligence?) After All (AA ... Achieved Availability, Audit Agent, Automatic Answer, Attack Assessment, Approval Authority), what better way to inflate weak ideas, obscure poor reasoning, and inhibit clarity than disguising your thoughts in an intimidating and Impenetrable Fog (IF ... Intermediate Frequency, Interface, Intelligence Fusion, Information Flow, Industrial Fund) of abbreviations?
Some acronyms are terribly APpropriaTe (APT). "Broad Agency Anouncement" (BAA) and "Base Standards" (BS) speak for themselves. And what happens when you tell your boss of a problem? A FRACAS (Failure Reporting, Analysis, and Corrective Action System) ensues.
Some are INAPpropriaTe (INAPT). Digital Research Inc.'s Graphical Environment Manager, a graphical user interface, wasn't such a GEM next to oh, say, MacOS or Windows. Are people who use the Tower Operator Training System (TOTS) childlike? Is the existence of an Anti-trust Management Information System a sign of something AMIS? And why did Apple Computer name it's Apple III Operating System (OS ... Open Source? Open System? Offensive System? Operational Suitability? Operational Sustainability? Operational Station? Operations and Support? Operations and Sustainment? Outfitting Support? Official Standard? Organization Standard? Office of the Secretary? Ocean Surveillance?) "SOS?" Hmmm ... maybe that one was appropriate...
Is there a solution? Of Course (OC: Optical Carrier)! Don't have a COW (Channel Order Wire, Chief Of the Watch). The Solution is Easy (SE? Second Edition? Support Equipment? Science and Engineering? System Engineer?). It should just be illegal to Create, Use, or Posses (CUP, but not a COMSEC Utility Program) an acronym. Period. I don't know what an Appropriate Punishment (AP; Acquisition Plan, Acquisition Program, Active/Passive, Adjunct Professor, Anomalous Propagation, Approval Procedures, Automation Planning, Access Protocol, Analysis Paper, Application Processor, Application Protocol, Array Processor, Adaptive Packet, Advanced Processor, All Points, Arithmetic Process) might be, but I've always wanted to see someone Drawn and Quartered (DQ ... Distributed Queue, Differential Quadrature, uh ... Dairy Queen). Otherwise we'll all just have to ADAPT (Architecture Design, Analysis and Planning Tool) to never knowing what anyone is talking about.
Appropriation vs Authorization
June 22, 2004 - Reading time: 2 minutes
This was in the FAA VOICE newsletter a while back; I just stumbled across it looking for something else but I thought it was pretty neat. The question is, what's the deal with "authorization" and "appropriation" in congress? You hear a lot (at least around budget time) about appropriation bills and whatnot, but I (and apparently others) never really understood what that meant.
Well, Deandra Brooks (from the FAA's Office of Government and Industry Affairs) offered the best explanation that I've ever seen:
"In congress, you have the Budget Committee, authorizing committees, and an appropriations committee. While much of their work is intertwined, they all do something a little different. But, like a 3-legged stool, we need support from each one. This is how it was explained to me; I hope it helps you better understand the distinctions."
"In a family, the dad is the Budget Committee. At the beginning of the year, he sits down and looks at the family's income and bills. He makes a list of mandatory spending - the mortgage, insurance payments, food, utilities, etc., and a list of discretionary spending - new clothes, vacations, restaurant dinners, etc. He comes up with a budget and tells the mom and kids that this is what they can and can't afford. The mom and kids quickly laugh at him."
"The kids are the authorizing committees. They are constantly complaining to mom and dad that they need new shoes, they want money to go to the movies, they should have a bigger allowance to buy the things they want like candy and comic books. They usually ask for more than they will ever get."
"Now mom is the appropriations committee. She holds the checkbook, the debit card, and the credit cards. If mom thinks that dad's budget doesn't include enough restaurant dinners, she'll just put it on a credit card. If mom thinks the kids should have ice cream, they get it; if she decides they don't need it, they don't. Because mom decides who and what gets funded, she has a lot of power."
So anyway, that's the scoop. Because I'm sure you were just dying to know...
Remember the Hindenburg!
May 6, 2004 - Reading time: ~1 minute
The German dirigible Hindenburg burned and crashed in Lakehurst, NJ on May 6, 1937; 36 of the 97 passengers and crew died. But the memory of the Hindenburg lives on, not only as a trite metaphor, but also as a short example in college freshman physics textbooks.
Three Mile Island
March 27, 2004 - Reading time: 23 minutes
Note 1 May 2020: I've made several minor edits to this while re-posting from the original blog. I don't think I'm changing anything critical; just readability.
Another note: the story of TMI here borrows heavily from Inviting Disaster: Lessons from the Edge of Technology, by James Chiles.
Final note: the end of this post is really disappointing. I actually have a lot to say on the subject of "operator error," and - by extension - "root cause analysis." As I recall, I had a lot to say about those things when I wrote this post, too; I just didn't actually say them. If I do start blogging again, it'll be about this.
March 28 marks the 25th anniversary of the accident at Three Mile Island! In honor of the occasion, I'd like to go on for a bit about it.
If we learn anything from history, we learn the most from historic failures. History provides us with many spectacular failures, and it is imperative that we learn from them.
The nuclear power industry provides us with some very spectacular failures indeed, and I'd like to ramble for a bit on a very important one: the accident at Three Mile Island.
The near-catastrophe at Three Mile Island (hereafter TMI) started in Unit 2 of the plant on March 28, 1979 and the resulting drama gripped the nation for weeks; as pregnant women were fleeing the area, the President Jimmy Carter toured the plant as two tiny pumps, designed for other tasks, worked to keep the core of the plant from melting (one of them eventually failed).
Unit 2 at TMI had a lot of problems at the end of 1978 when it was set to be started. Nuclear plants are complex, though, so startup problems are not so unusual. Adding to the normal complexity, however, was the fact that the maintenance crews were overworked at the time of the accident - crew sizes had been reduced in an effort to save money. The unit was plagued with various problems, and was shut down several times (after the accident, in 1982, the utility owner Metropolitan Edison sued the reactor's builder, Babcock and Wilcox for building a faulty reactor; B&W fired back with a lawsuit charging that the Edison employees were not competent to run the reactor).
Most commercial nuclear reactors have two cooling systems. The primary system contains water at high pressure and temperature that circulates through the core where the reaction takes place. This water goes to the steam generator, where it flows around tubes which circulate water in the secondary cooling system. The resulting heat transfer keeps the core from overheating, and the heat from the secondary system generates steam that runs the turbine. The accident started in the secondary system.
Water in the primary system is highly radioactive, but water in the secondary system is not. However, the water in the secondary system must be very pure, because its steam drives turbine blades in a system that is built to extremely tight tolerances. Contaminants in the water must be removed by the condensate polisher system, to avoid gunking up the system and lowering its efficiency, or (worse) causing premature wear and failure of the turbine blades. The condensate polisher design used at TMI was a somewhat brittle design, and this particular one had failed three times in the few months the reactor had been in operation. On March 28, 1979, after operating for about 11 hours, the turbine "tripped" (stopped) at 4:00am. The plant operators did not know why at the time, but the turbine tripped because a small amount of water (maybe a cupful) leaked through a seal into the instrument air system of the plant. This system drives several of the plant's instruments. When water leaked into the system, it interrupted the air pressure on two valves at two feedwater pumps. Normally, if air pressure was lost at these two pumps it would mean that something was wrong; in this case nothing was wrong that should make the pumps stop, but they did anyway: in this case, the behavior was by design; the driving signal was the problem.
But without the pumps, cold water was no longer flowing into the steam generator to cool the reactor, so the turbine shut down automatically. The system that did this is known as an Automatic Safety Device (ASD).
Stopping the turbine in a nuclear reactor doesn't make it safe, though. The core was still hot, and it needed to be cooled down. No problem, there was another ASD for this purpose -- emergency feedwater pumps started; they pulled water from an emergency storage tank and ran it through the secondary cooling system.
Or at least they were supposed to. But the pipes from the emergency feedwater pumps were blocked -- a valve in each pipe had been left closed after maintenance two days earlier. So the operator verified that the pumps came on as they should, but he did not know that they were not pumping water.
There were two indicators on TMI's control panel that showed that the valves were closed (though one was obscured by a repair tag hanging from the switch above it). But at this point, there was no reason to suspect a problem with the valves. Eight minutes later, when the operators were otherwise baffled by the operation of the plant, they discovered the light, but at that point it was too late.
But we're not there yet. Now, just as the emergency feedwater pumps have started, things should be fine, but since there was actually no coolant circulating in the secondary coolant system, the steam generator boiled dry. Because of this, no heat was being removed from the reactor core, so the reactor "scrammed." (When the reactor scrams, graphite control rods drop into the core to absorb neutrons and stop the reaction. In early experiments with nuclear power, so the lore says, the procedure was to "drop the rods and scram" -- hence the name).
But that's not enough to avert catastrophe. The decaying radioactive materials still produce heat (in this case, enough to generate electricity for over 15,000 homes for a useful amount of time); this "decay heat" builds up a large amount of pressure in the 40 foot tall stainless steel vessel that houses the reactor. Normally, there are thousands of gallons of water to draw off this heat, and it would cool down within a few days. But - of course - in this case, the cooling system was not working.
Thankfully, there are more ASDs to handle this problem. The first is called the Pilot Operated Relief Valve (PORV), which relieves pressure in the core by channeling water from the core through a large vessel called a pressurizer, and then out the top of it into a drain pipe (the "hot leg"), and from there down into a sump. This water would be radioactive and very hot. By design, the PORV should only be open long enough to relieve excess pressure. The liquid water coolant is only a liquid because it's under pressure; if the valve stays open for too long, the pressure in the core drops enough that the remaining water can boil and turn into steam. The steam bubbles (called "steam voids") that would result in the core and primary cooling pipes would restrict the flow of coolant, and allow some spots (in particular, some spots around the uranium rods) to overheat.
The PORV at TMI was manufactured by Dresser Industries; in the aftermath of the accident, Dresser ran TV ads claiming that Jane Fonda, who was then starring in the movie China Syndrome, was more dangerous than nuclear plants. The valve, per its specification, had a Mean Time Between Failure (MTBF) of fifty usages; this seems pretty low but in this case was seen as OK because with any amount of luck, it almost never be used. Contrary to this, the President's Commission on the TMI accident turned up at least eleven instances of the same PORV failing in other nuclear plants (much to the surprise of the Nuclear Regulatory Commission, and B&W, who only knew of four), including two earlier failures at TMI's Unit 2. It also failed this time, when the emergency feedwater pumps' block valves were closed, the condensate pumps were out of order, and one important indicator light was obscured: after opening, the PORV failed to reseat properly when it was supposed to close.
This meant that the reactor core, which was heating up rapidly, had a big hole in the top - the stuck valve. The coolant remaining in the core was under very high pressure, and was shooting out of the stuck valve into the hot leg pipe, which went down to its drain tank. When all was said and done, 32,000 gallons (about 1/3 the capacity of the core) went out of the core through that pipe. This was bad news.
But engineers are always thinking. Since it was already known that the valve was a bit touchy (in all fairness, it's hard to make something reliable under such extreme circumstances), an indicator had been recently added to warn operators if it did not reseat. Sadly, that indicator was also broken - it indicated that all was well. This is the worst sort of failure: if there had been no status indicator, someone might have actually taken a walk and checked to see if the valve had reseated, and some problems might have been avoided. It's just one of those cases where it might have been better to have no indicator at all -- after all, if you can't believe your warning lights, what good are they?
The indicator said that the valve had shut, so the operators waited for the reactor pressure to rise again (it had dropped sharply, as one would expect, when the valve opened). The valve stayed stuck, partially open, for another 2 hours and 20 minutes until a new shift supervisor, taking a fresh look at the problems, discovered it.
But we're not there yet -- incredibly, with this cavalcade of broken features and minor screwups we're still just thirteen seconds into the accident. Just for review; in these thirteen seconds, the relevant problems were:
- A false signal caused the condensate pumps to turn off
- Two valves for emergency cooling were closed instead of opened
- The indicators that would have alerted operators to #2 was obscured
- The PORV opened properly, then failed to reseat
- The indicator that would indicate the PORV's failure also failed
... only #3 in this list could possibly lead to blaming the operators. It should also be pointed out that no single failure there suggests a link to other failures; in fact they are all on different parts of the system. Additionally, none of the problems by themselves would be a big deal - it is what is sometimes called a "swiss cheese catastrophe," where holes in all of the layers of protection just happen to line up so that a catastrophic failure occurs.
Adding to the complexity of the situation, it was later found out that the radioactive water from the hot leg was not even flowing into the tank designed to hold it; it had been misrouted to another tank, which ended up overflowing onto the floor in an auxiliary building.
But let's rewind back to our point 13 seconds into the event. The PORV was open, and would be for another two hours and twenty minutes; coolant from the reactor core was squirting out of it, which meant that reactor pressure dropped. This is dangerous. If the pressure goes down, the superheated water (over 2,000°F) will turn into steam, which does not work to cool the reactor; steam bubbles also block liquid flow in the coolant pipes.
But (thank goodness!) yet another ASD kicked in. One of two reactor coolant pumps restarted automatically, and the other was manually started by the operators (this was quick action: remember we're still around 13 seconds in to the event). For a few minutes, this appeared to do the trick; pressure appeared to be stabilizing in the core.
But it actually wasn't stabilizing; the indicators only said it was. Why? The operators were not aware that the steam generators were not getting water. When they boiled dry, the reactor coolant started heating up again because the secondary cooling system was not removing heat from the primary one, which removes heat from the core. And since the core was losing water, pressure in the coolant system dropped sharply.
Two minutes into the accident, yet another ASD (whew!) came on. This one - a hail-Mary pass - is called High Pressure Injection (HPI), and it forces water into the core at an extremely high rate. This is a key moment in the accident, and the operators' actions here earned them the unreasonable distinction of being the "cause" of the accident. They let the HPI go full blast for about two minutes, and then cut it way back. When they cut it back, it stopped replacing the water that was boiling out through the (still open) PORV, so the core was steadily being uncovered. This is the worst possible case in a nuclear plant, because if the core is uncovered it will melt through the vessel and may release radiation into the open.
Let's get a bit of background on HPI and its relation to the problem. HPI involves the injection of a lot of cold water at a very high pressure into the very hot reactor core in order to cool it. The water goes in at about 1,000 gallons per minute (this would fill an average-sized suburban swimming pool in about 20 minutes). It is viewed by many as risky, because the thermal shock could cause cracks in the core vessel. It could also cause problems if the core vessel fills with water. The dangers here weren't well understood, and there was a lot of disagreement at the time over whether or not it was a good idea to throttle back the HPI. As an aside - two years later, the NRC issued a report disclosing that thirteen reactors, some of them only three years old, showed degrees of core vessel brittleness because the radioactive bombardment of the vessel was greater than predicted; in these cases, the injection of cold water into a brittle vessel would be very likely to crack it. Fortunately, however, the TMI reactor had only been in operation at full power for about 40 days, so HPI did not pose this particular risk.
The more widely disputed problem with HPI involves the pressurizer. Remember that the pressurizer is connected directly to the core vessel via the PORV. The pressurizer, under normal conditions, contains about 800 cubic feet of water, resting under about 700 cubic feet of steam. This ratio is controlled by the use of heaters in the tank. The idea is that the steam acts as a shock absorber: liquid water is incompressible, but steam is not, so if there is a substantial pressure surge in the core, the cushion provided by the steam would prevent coolant pipes from bursting. A burst coolant pipe is one source of a Loss Of Coolant Accident (LOCA), which could cause a core meltdown, so this is seen as a critical system. Under HPI, the incoming water could increase pressure in the pressurizer by flooding it with water too quickly for heaters to manage the steam/water split, so it would fill with water and no longer act as a shock absorber. The general consensus at the time was that allowing the pressurizer to be filled with water ("going solid" - solid water with no steam) was a Bad Thing and should be avoided. In fact, the TMI operating manual said, with unusual clarity, that the pressurizer "must not be filled with coolant to solid conditions (400 inches) at any time except as required for system hydrostatic tests." (emphasis mine)
So: the operators of the plant were trained to avoid going solid in the pressurizer by both the manufacturer (B&W) and the owner (Metropolitan Edison). There was never any instruction that suggested that going solid in the pressurizer might be OK -- this would be like telling your kids "sometimes it's OK to put a plastic bag over your head." In fact, such an instruction (that going solid in the pressurizer during HPI could be acceptable) was considered and rejected by B&W after an earlier accident at a different plant.
But at this point, about two minutes into the incident, going solid in the pressurizer would have been a good risk to take, because - unbeknownst to the operators - the reactor core was about to be uncovered.
When HPI was activated, the operators were looking primarily at two dials, which were close to each other on the huge indicator panel. One indicated that the pressure in the reactor was falling, but the other indicated that the pressure in the pressurizer was dangerously high and rising. This was weird, because the two are directly connected by a large pipe, and the two dials always moved together. After all: the pressurizer is there to control the pressure in the coolant system. That's what it's for. The pressures should always be the same, and to see the dials moving differently meant, in a reasonable world, that one of them was probably wrong. Given TMI's short and troubled upbringing; a gauge being faulty would not be too surprising.
But which one was wrong? If the reactor dial was correct, there must be a huge problem, because plenty of water was entering the reactor vessel through the reactor cooling pumps (which were still running), and more obviously, HPI - which was still running. Even if there was a small pipe break somewhere, the reactor cooling pumps would easily keep the core covered. On the other hand, since the emergency feedwater pumps were on, the operators thought that the secondary cooling system should be cooling the core, so the core pressure should really be falling. If that was true, then the HPI signal had been wrong. So perhaps the reactor pressure dial was wrong.
The pressurizer pressure dial, though, was a serious cause for concern. High pressure in the pressurizer eliminated a safety margin, and all instruction that the operators had said that the pressurizer should never be flooded. The pressurizer was the first line of defense between the operators and a LOCA. It was easy to see the connection between HPI and rising pressure in the pressurizer - HPI was flooding the core and sending water up to flood the pressurizer. Given the information at hand, this seemed pretty obvious.
So the operators cut the HPI way back ("throttled back on the makeup valves"). Pressure in the pressurizer started coming back down, relieving the danger of going solid. This was Good.
What the operators didn't know was that the emergency feedwater pumps didn't have any water to pump (remember the closed valves?), and also the PORV was stuck open: they already had a significant LOCA, but not from a pipe break. The rise in pressure in the pressurizer was probably due to steam voids which were rapidly forming because the core was close to becoming uncovered. The operators thought they were avoiding a LOCA by throttling back HPI, but in fact they were already in one, and throttling back HPI only made it worse. With the PORV stuck open, the danger of going solid in the pressurizer was reduced because the open valve would provide some relief. But nobody in the control room knew it was open.
The Kemeny Commission thought that the operators should have known all of this - instead, the report says, they were "oblivious" to the danger; the two readings "should have clearly alerted" them to the LOCA; "the major cause of the accident was due to inappropriate actions by those who were operating the plant."
It's easy to make those sorts of judgments after the fact. It's easy for us, decades later, to pontificate about what the operators should have known, and how they could have known it. Back in the 1970s, though, these events transpired as we understand them and the damage was done. Anyway, about 4 or 5 minutes into the event, another more pressing problem arose.
The reactor coolant pumps that had turned on started thumping and shaking. They could be heard and felt from the control room, which was pretty far away. Should the pumps be turned off? A hasty conference was called, and they were turned off. In retrospect, the noise was a sign of further dangers ahead: the pumps were cavitating, because they were not getting enough coolant flowing through them to function correctly.
At this point, a few minutes into the event, there were three audible alarms sounding in the control room. Many of the 1,600 warning indicators (lights and rectangular displays with code numbers and letters on them) were on or blinking. The operators wanted to turn off the main alarm Klaxon, but they couldn't because turning it off would also cancel some of the warning lights, and they needed those to be correct. So it was a little hard to concentrate: a Klaxon going, hundreds of warning lights flashing, a dot matrix printer printing line after line of status information. Also remember that this was the 1970s: there were no smartphones, and there was no internet - the control room had one phone line to the outside world, and that was the only way to ask for help (if you could hear it over the Klaxon). And computers? There was a status monitoring computer, but it was not in the control room. It was housed in a server room: pretty powerful for its day, and capable of recording information about hundreds of alarm inputs as fast as they came in, but its output went to a dot matrix printer in the control room that could only print fifteen lines of information per minute. The printer fell more than two hours behind at one point in the event.
In the meantime, radiation alarms were starting to happen in various parts of the reactor facility, and the control room was slowly filling with experts. By the end of the day, adding to the din, there were almost 40 people in the control room.
But rewind again. Two hours and twenty minutes after the start of the incident, a new shift came on. It was at this point that the new shift supervisor decided to check the PORV, and the operators discovered that the valve was stuck. They closed a block valve to shut off the flow to the PORV. An operator testifying before the Kemeny Commission hearings said that it was more of an act of desperation than understanding to shut off the block valve: after all, you don't casually block off a safety system.
That act of desperation was, in retrospect, well done. But another problem was brewing.
The fuel rods, 36,816 in this reactor, contain enriched uranium in little pills, all stacked within a thin liner of zirconium. Water circulates through the 12 foot stacks of rods and cools the liner ("cladding") so it won't melt. If they get too hot, though, the cladding can react with the water: a zirconium-water reaction. This consumes Oxygen, thus releasing Hydrogen. The Hydrogen bubbles form pockets of Hydrogen gas, and these pockets coalesced to form the famous Hydrogen bubble that threatened the integrity of the plant for the next few days. Any spark could have ignited the Hydrogen and brought the entire plant down to a glowing, fiery pile of Chernobyl-esque rubble. There were several warning signs that a Hydrogen bubble was being produced, and that a smaller one had already exploded (the explosion caused a pressure spike that reached half the design limit of the building). With more and more Hydrogen being produced, the gas might have found ways to be vented from the core (whose condition was unknown) into the containment building, where a spark from (for example) starting a pump could have ignited it; if that happened near heavy equipment, the shrapnel could have broken through the core or otherwise injured people. Three years after the incident, investigators found that the huge crane required to lift off the top of the reactor vessel had been damaged by missiles from the small explosion of the first Hydrogen bubble; two engineers protested that the crane was not safe enough to use and were fired.
At this point, we've demonstrated the sitcom version of relativity by breezing through a hot but complex topic in just a couple of pages. There's a lot to say about TMI. In particular, there's a lot to say about what it tells us about government procurement, the commercial nuclear power industry in the US, the safety of complex systems, human behavior, and ... really lots of stuff. TMI was, if nothing else, a goldmine of research opportunity, which was mostly squandered by greedy, shortsighted, intellectually lazy people.
That said, there is still much to learn about the interaction of failures in complex systems here. There is also much to learn about the dangers of implementing such a complex system whose failure could cause huge problems.
My hope is that we also learn that blaming the operators, while often a good PR move, solves no problems. More on this maybe later. Pleasant dreams, all.
UltraSPARC Sucks.
February 13, 2004 - Reading time: 3 minutes
I have officially decided that Sun's computing platform, and in particular the UltraSPARC processor, suck. Also, there is no good OS to run on it. Solaris is one of the worst operating systems I've ever tried to use, and Linux has horrible SPARC support.
But back to the UltraSPARC, Sun's flagship pile of ass. Here's a chip that has changed minimally, architecturewise, since its introduction. To push the chip's clock speed past 1GHz (when Intel and AMD were tossing out 2GHz+ chips as fast as people would buy them), TI had to use a six-layer copper interconnect process -- the Pentium 4 and Athlon chips only use 4 layers. The fact is, for the last 10 years or so, the UltraSPARC has been the slowest RISC chip out there. Sun has relied on anti-Microsoft and anti-PC sentiment to sell computers, not technical features or performance.
And the UltraSPARC-III? It's just a mildly-tweaked UltraSPARC-II, with slightly more more cache, and slightly faster clocks (though still not up to par with any competition). And don't get me started on the circular register file. Too late, I'm started:
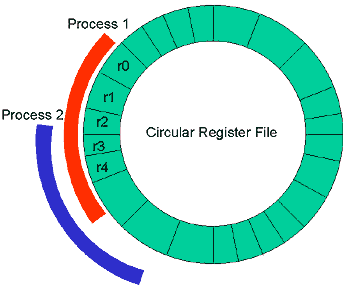
SPARC chips expose 32 registers to each program, but the registers are actually a window into the larger set of registers -- the rest are hidden from view until you call a different subroutine, function, or program. The idea was that where other processors would push parameters onto a stack and let the called subroutine pop them off, here the SPARC processor will slide (rotate) the window to give the new subroutine a fresh set of registers. The old and new windows overlap, so some registers are shared. Neat in concept, but not so neat when you actually implement it. For one thing, it's still a finite number of registers, so when you run out it's back to pushing and popping like normal processors. And since you don't have a full view of the register, you can't predict when the register will underflow or overflow, so performance can be unpredictable, especially under heavy loads. Oh, yea, the processor doesn't handle under/overflow in hardware; it generates a software fault instead, so the OS has to handle it (using lots more cycles). Yay! The window sliding method also requires hugely complex multiplexers and register ports so that any physical register looks like any logical register.
Not to mention that the physical register layout is stupid, and requires a huge amount of extra wiring because it forms a ring around a large chunk, but not all, of the rest of the processor, so you've got to run interconnects over, around, and through the register file.
Anyway, the point is that the UltraSPARC sucks. I'll get into this a bit more later tonight, but first I'm going to eat.
The mother of invention
February 10, 2004 - Reading time: 4 minutes
You've probably heard the saying "Necessity is the mother of invention" a few times. The phrase implies that necessity springs out of the blue, and that civilization ceases to function until whatever sudden pressing need has been satisfied. At best, the phrase is a tautology. At worst, it is an indication that the speaker of the phrase is the sort of simple-minded fool that spouts trite expressions without giving thought to reality.
If you were to step back and take stock of your surroundings right now, you would be hard pressed to find anything that you need that isn't somehow provided for. You aren't special -- it's like that for everybody. And everybody now isn't special, either: people who lived in the 1800s had everything they needed as well; so did the people living in prehistoric times. The technology and other "things" that exist in a given time define that era; that is to say that our tools are, by definition, adequate for living in our world, just as the tools of cavemen were adequate for living in prehistoric times. Citizens of the world didn't wake up one morning in 1923 and realize that nobody could go on living until the television was invented; they had other perfectly adequate means (such as radio or print) to distribute news and entertainment. The Wright brothers didn't realize, 100 years ago, that civilization would collapse if they weren't able to get an airplane to fly. And, heartless as it may seem, if nobody stumbled across Penicillin, there might be fewer of us around, but we'd still be here.
Some people choose to invert the phrase; they say "invention is the mother of necessity." It's a tempting thought -- first we invent the horse-drawn carriage, then we invent the automobile to replace the carriage, but to make the automobile more palatable, we must invent power steering, cruise control, leather seats, huge stereo systems, radar-assisted parking systems, etc. A more interesting example is that of the tin can. One would suspect that the invention of the tin can would necessitate the immediate invention of the can opener. But while the tin can was first presented in 1810, the first useful can opener didn't appear until nearly 50 years later. In reaction to this, the mind's eye conjures up amusing images of an entire generation of hungry Victorians starving and contemplating the bitter irony of life as they stared at shelves full of canned foods; but fortunately it wasn't so. Instead, people looked at their surroundings and used what they had. For example, a tin containing roast veal carried on the explorer William Edward Parry's Arctic expedition in 1824 included the following instructions for opening: "Cut round on the top with a chisel and hammer." Soldiers fighting in the American Civil War opened their canned rations with knives, bayonets, and even rifle fire. The earliest purpose-built can openers were cumbersome, complicated gadgets that were owned by shopkeepers, which was unfortunate because opening your cans at the checkout register defeats the purpose of having the stuff canned in the first place. William Underwood, who established America's first cannery in the 1920s, advised his customers to use whatever tools were around the house to open the cans.
As Thomas Edison wrote, "Restlessness is discontent -- and discontent is the first necessity of progress." Surely, inconvenience breeds restlessness, and it's not too hard to see that there was no convenient method for most people to open tin cans; this inconvenience was what got Ezra Warner of Waterbury, CT thinking in her spare time, and eventually led to her landmark 1858 patent for a can opener that just about anybody could use. It worked well enough, but its use left cans with sharp, jagged edges. Although a nasty cut to the finger is most often not fatal, it can be inconvenient, and in 1870, because of this, William Lyman of West Meriden, CT, patented the first can opener to use a wheel-shaped blade which made a smooth, continuous edge.
The story goes on, but perhaps you see the point I'm getting at -- necessity is not the mother of invention, and invention is not the mother of necessity. Inconvenience is the mother of invention; necessity is already provided for,
or else we wouldn't be here. I make the (bold? foolish?) claim that nothing that has ever been invented has been necessary; new items are only invented to improve upon the perceived shortcomings of existing items. Don't believe me? Look around your desk; pick up anything, and think: what need went unfulfilled before this thing was invented? What would people have ever done without it? I assure you, nothing man-made predates man, so somewhere along the line, someone got along without anything that we've invented so far. They may not have liked getting along without it, but that's why it's here today -- because it just makes life so much more convenient.